Seq2Seq for LaTeX generation
Seq2Seq for LaTeX generation - part II
githubThis post is the second in a series about im2latex: its goal is to explain
- how to adapt a seq2seq model for LaTeX generation
- how to implement it in Tensorflow.
If you are not familiar with seq2seq
 |
Code is available on github. Though designed for image to LaTeX (im2latex challenge), it could be used for standard seq2seq with very little effort.
Introduction
As an engineering student, how many times did I ask myself
How amazing would it be if I could take a picture of my math homework and produce a nice LaTeX file out of it?
This thought has been obsessing me for a long time (and I’m sure I’m not the only one) and since I’ve started studying at Stanford, I’ve been eager to tackle the problem myself. Except from some work by Havard’s NLP group and this cool website), few solutions were available. I hypothesized that the problem was not that easy and chose to wait until the amazing computer vision class to tackle the problem.
This problem is about producing a sequence of tokens from an image, and is thus at the intersection of Computer Vision and Natural Language Processing.
Approach
Part I covered the concepts of sequence-to-sequence applied to Machine Translation. The same framework can be applied to our LaTeX generation problem. The input sequence would just be replaced by an image, preprocessed with some convolutional model adapted to OCR (in a sense, if we unfold the pixels of an image into a sequence, this is exactly the same problem). This idea proved to be efficient for image captioning (see the reference paper Show, Attend and Tell). Building on some great work from the Harvard NLP group, my teammate Romain and I chose to follow a similar approach.
Keep the seq2seq framework but replace the encoder by a convolutional network over the image!
Good Tensorflow implementations of such models were hard to find. Together with this post, I am releasing the code and hope some will find it useful. You can use it to train your own image captioning model or adapt it for a more advanced use. The code does not rely on the Tensorflow Seq2Seq library as it was not entirely ready at the time of the project and I also wanted more flexibility (but adopts a similar interface).
We’ll assume familiarity with Seq2Seq covered in part I
Data
To train our model, we’ll need labeled examples: images of formulas along with the LaTeX code used to generate the images. A good source of LaTeX code is arXiv, that has thousands of articles under the .tex format. After applying some heuristics to find equations in the .tex files, keeping only the ones that actually compile, the Harvard NLP group extracted $ \sim 100, 000 $ formulas.
Wait… Don’t you have a problem as different LaTeX codes can give the same image?
Good point: (x^2 + 1) and \left( x^{2} + 1 \right) indeed give the same output. That’s why Harvard’s paper found out that normalizing the data using a parser (KaTeX) improved performance. It forces adoption of some conventions, like writing x ^ { 2 } instead of x^2, etc. After normalization, they end up with a .txt file containing one formula per line that looks like
\alpha + \beta
\frac { 1 } { 2 }
\frac { \alpha } { \beta }
1 + 2
From this file, we’ll produce images 0.png, 1.png, etc. and a matching file mapping the image files to the indices (=line numbers) of the formulas
0.png 0
1.png 1
2.png 2
3.png 3
The reason why we use this format is that it is flexible and allows you to use the pre-built dataset from Harvard (You may need to use the preprocessing scripts as explained here). You’ll also need to have pdflatex and ImageMagick installed.
We also build a vocabulary, to map LaTeX tokens to indices that will be given as input to our model. If we keep the same data as above, our vocabulary will look like
+
1
2
\alpha
\beta
\frac
{
}
Model
Our model is going to rely on a variation of the Seq2Seq model, adapted to images. First, let’s define the input of our graph. Not surprisingly we get as input a batch of black-and-white images of shape $ [H, W] $ and a batch of formulas (ids of the LaTeX tokens):
# batch of images, shape = (batch size, height, width, 1)
img = tf.placeholder(tf.uint8, shape=(None, None, None, 1), name='img')
# batch of formulas, shape = (batch size, length of the formula)
formula = tf.placeholder(tf.int32, shape=(None, None), name='formula')
# for padding
formula_length = tf.placeholder(tf.int32, shape=(None, ), name='formula_length')
A special note on the type of the image input. You may have noticed that we use
tf.uint8. This is because our image is encoded in grey-levels (integers from0to255- and $ 2^8 = 256 $). Even if we could give atf.float32Tensor as input to Tensorflow, this would be 4 times more expensive in terms of memory bandwith. As data starvation is one of the main bottlenecks of GPUs, this simple trick can save us some training time. For further improvement of the data pipeline, have a look at the new Tensorflow data pipeline.
Encoder
High-level idea Apply some convolutional network on top of the image an flatten the output into a sequence of vectors $ [e_1, \dots, e_n] $, each of those corresponding to a region of the input image. These vectors will correspond to the hidden vectors of the LSTM that we used for translation.
Once our image is transformed into a sequence, we can use the seq2seq model!
 |
We need to extract features from our image, and for this, nothing has (yet) been proven more effective than convolutions. Here, there is nothing much to say except that we pick some architecture that has been proven to be effective for Optical Character Recognition (OCR), which stacks convolutional layers and max-pooling to produce a Tensor of shape $ [H’, W’, 512] $
# casting the image back to float32 on the GPU
img = tf.cast(img, tf.float32) / 255.
out = tf.layers.conv2d(img, 64, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, 2, 2, "SAME")
out = tf.layers.conv2d(out, 128, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, 2, 2, "SAME")
out = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, (2, 1), (2, 1), "SAME")
out = tf.layers.conv2d(out, 512, 3, 1, "SAME", activation=tf.nn.relu)
out = tf.layers.max_pooling2d(out, (1, 2), (1, 2), "SAME")
# encoder representation, shape = (batch size, height', width', 512)
out = tf.layers.conv2d(out, 512, 3, 1, "VALID", activation=tf.nn.relu)
Now that we have extracted some features from the image, let’s unfold the image to get a sequence so that we can use our sequence to sequence framework. We end up with a sequence of length $ [H’ \times W’] $
H, W = tf.shape(out)[1:2]
seq = tf.reshape(out, shape=[-1, H*W, 512])
Don’t you loose a lot of structural information by reshaping? I’m afraid that when performing attention over the image, my decoder won’t be able to understand the location of each feature vector in the original image!
It turns out that the model manages to work despite this issue, but that’s not completely satisfying. In the case of translation, the hidden states of the LSTM contained some positional information that was computed by the LSTM (after all, LSTM are by essence sequential). Can we fix this issue?
Positional Embeddings I decided to follow the idea from Attention is All you Need that adds positional embeddings to the image representation (out), and has the huge advantage of not adding any new trainable parameter to our model. The idea is that for each position of the image, we compute a vector of size $ 512 $ such that its components are $ \cos $ or $ \sin $. More formally, the (2i)-th and (2i+1)-th entries of my positional embedding $ v $ at position $ p $ will be
where $ f $ is some frequency parameter. Intuitively, because $ \sin(a+b) $ and $ \cos(a+b) $ can be expressed in terms of $ \sin(b)$ , $ \sin(a)$ , $ \cos(b)$ and $ \cos (a) $, there will be linear dependencies between the components of distant embeddings, authorizing the model to extract relative positioning information. Good news: the tensorflow code for this technique is available in the library tensor2tensor, so we just need to reuse the same function and transform our out with the following call
out = add_timing_signal_nd(out)
Decoder
Now that we have a sequence of vectors $ [e_1, \dots, e_n] $ that represents our input image, let’s decode it! First, let’s explain what variant of the Seq2Seq framework we are going to use.
First hidden vector of the decoder’s LSTM In the seq2seq framework, this is usually just the last hidden vector of the encoder’s LSTM. Here, we don’t have such a vector, so a good choice would be to learn to compute it with a matrix $ W $ and a vector $ b $
\[h_0 = \tanh\left( W \cdot \left( \frac{1}{n} \sum_{i=1}^n e_i\right) + b \right)\]This can be done in Tensorflow with the following logic
img_mean = tf.reduce_mean(seq, axis=1)
W = tf.get_variable("W", shape=[512, 512])
b = tf.get_variable("b", shape=[512])
h = tf.tanh(tf.matmul(img_mean, W) + b)
Attention Mechanism We first need to compute a score $ \alpha_{t’} $ for each vector $ e_{t’} $ of the sequence. We use the following method
\[\begin{align*} \alpha_{t'} &= \beta^T \tanh\left( W_1 \cdot e_{t'} + W_2 \cdot h_{t} \right)\\ \bar{\alpha} &= \operatorname{softmax}\left(\alpha\right)\\ c_t &= \sum_{i=1}^n \bar{\alpha}_{t'} e_{t'}\\ \end{align*}\]This can be done in Tensorflow with the follwing code
# over the image, shape = (batch size, n, 512)
W1_e = tf.layers.dense(inputs=seq, units=512, use_bias=False)
# over the hidden vector, shape = (batch size, 512)
W2_h = tf.layers.dense(inputs=h, units=512, use_bias=False)
# sums the two contributions
a = tf.tanh(W1_e + tf.expand_dims(W2_h, axis=1))
beta = tf.get_variable("beta", shape=[512, 1], dtype=tf.float32)
a_flat = tf.reshape(a, shape=[-1, 512])
a_flat = tf.matmul(a_flat, beta)
a = tf.reshape(a, shape=[-1, n])
# compute weights
a = tf.nn.softmax(a)
a = tf.expand_dims(a, axis=-1)
c = tf.reduce_sum(a * seq, axis=1)
Note that the line
W1_e = tf.layers.dense(inputs=seq, units=512, use_bias=False)is common to every decoder time step, so we can just compute it once and for all. The dense layer with no bias is just a matrix multiplication.
Now that we have our attention vector, let’s just add a small modification and compute an other vector $ o_{t-1} $ (as in Luong, Pham and Manning) that we will use to make our final prediction and that we will feed as input to the LSTM at the next step. Here $ w_{t-1} $ denotes the embedding of the token generated at the previous step.
\[\begin{align*} h_t &= \operatorname{LSTM}\left( h_{t-1}, [w_{t-1}, o_{t-1}] \right)\\ c_t &= \operatorname{Attention}([e_1, \dots, e_n], h_t)\\ o_{t} &= \tanh\left(W_3 \cdot [h_{t}, c_t] \right)\\ p_t &= \operatorname{softmax}\left(W_4 \cdot o_{t} \right)\\ \end{align*}\]\(o_t\) passes some information about the distribution from the previous time step as well as the confidence it had for the predicted token
and now the code
# compute o
W3_o = tf.layers.dense(inputs=tf.concat([h, c], axis=-1), units=512, use_bias=False)
o = tf.tanh(W3_o)
# compute the logits scores (before softmax)
logits = tf.layers.dense(inputs=o, units=vocab_size, use_bias=False)
# the softmax will be computed in the loss or somewhere else
If I read carefully, I notice that for the first step of the decoding process, we need to compute an $ o_0 $ too, right?
This is a good point, and we just use the same technique that we used to generate $ h_0 $ but with different weights.
Training
We’ll need to create 2 different outputs in the Tensorflow graph: one for training (that uses the
formulaand feeds the ground truth at each time step, see part I) and one for test time (that ignores everything about the actualformulaand uses the prediction from the previous step).
AttentionCell
We’ll need to encapsulate the reccurent logic into a custom cell that inherits RNNCell. Our custom cell will be able to call the LSTM cell (initialized in the __init__). It also has a special recurrent state that combines the LSTM state and the vector $ o $ (as we need to pass it through). An elegant way is to define a namedtuple for this recurrent state:
AttentionState = collections.namedtuple("AttentionState", ("lstm_state", "o"))
class AttentionCell(RNNCell):
def __init__(self):
self.lstm_cell = LSTMCell(512)
def __call__(self, inputs, cell_state):
"""
Args:
inputs: shape = (batch_size, dim_embeddings) embeddings from previous time step
cell_state: (AttentionState) state from previous time step
"""
lstm_state, o = cell_state
# compute h
h, new_lstm_state = self.lstm_cell(tf.concat([inputs, o], axis=-1), lstm_state)
# apply previous logic
c = ...
new_o = ...
logits = ...
new_state = AttentionState(new_lstm_state, new_o)
return logits, new_state
Then, to compute our output sequence, we just need to call the previous cell on the sequence of LaTeX tokens. We first produce the sequence of token embeddings to which we concatenate the special <sos> token. Then, we call dynamic_rnn.
# 1. get token embeddings
E = tf.get_variable("E", shape=[vocab_size, 80], dtype=tf.float32)
# special <sos> token
start_token = tf.get_variable("start_token", dtype=tf.float32, shape=[80])
tok_embeddings = tf.nn.embedding_lookup(E, formula)
# 2. add the special <sos> token embedding at the beggining of every formula
start_token_ = tf.reshape(start_token, [1, 1, dim])
start_tokens = tf.tile(start_token_, multiples=[batch_size, 1, 1])
# remove the <eos> that won't be used because we reached the end
tok_embeddings = tf.concat([start_tokens, tok_embeddings[:, :-1, :]], axis=1)
# 3. decode
attn_cell = AttentionCell()
seq_logits, _ = tf.nn.dynamic_rnn(attn_cell, tok_embeddings, initial_state=AttentionState(h_0, o_0))
Loss
Code speaks for itself
# compute - log(p_i[y_i]) for each time step, shape = (batch_size, formula length)
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=seq_logits, labels=formula)
# masking the losses
mask = tf.sequence_mask(formula_length)
losses = tf.boolean_mask(losses, mask)
# averaging the loss over the batch
loss = tf.reduce_mean(losses)
# building the train op
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss)
and when iterating over the batches during training, train_op will be given to the tf.Session along with a feed_dict containing the data for the placeholders.
Decoding in Tensorflow
Let’s have a look at the Tensorflow implementation of the Greedy Method before dealing with Beam Search
Greedy Search
While greedy decoding is easy to conceptualize, implementing it in Tensorflow is not straightforward, as you need to use the previous prediction and can’t use dynamic_rnn on the formula. There are basically 2 ways of approaching the problem
- Modify our
AttentionCellandAttentionStateso thatAttentionStatealso contains the embedding of the predicted word at the previous time step,AttentionState = namedtuple("AttentionState", ("lstm_state", "o", "embedding")) class AttentionCell(RNNCell): def __call__(self, inputs, cell_state): lstm_state, o, embbeding = cell_state # compute h h, new_lstm_state = self.lstm_cell(tf.concat([embedding, o], axis=-1), lstm_state) # usual logic logits = ... # compute new embeddding new_ids = tf.cast(tf.argmax(logits, axis=-1), tf.int32) new_embedding = tf.nn.embedding_lookup(self._embeddings, new_ids) new_state = AttentionState(new_lstm_state, new_o, new_embedding) return logits, new_stateThis technique has a few downsides. It doesn’t use
inputs(which used to be the embedding of the gold token from theformulaand thus we would have to calldynamic_rnnon a “fake” sequence). Also, how do you know when to stop decoding, once you’ve reached the<eos>token? - Implement a variant of
dynamic_rnnthat would not run on a sequence but feed the prediction from the previous time step to the cell, while having a maximum number of decoding steps. This would involve delving deeper into Tensorflow, usingtf.while_loop. That’s the method we’re going to use as it fixes all the problems of the first technique. We eventually want something that looks likeattn_cell = AttentionCell(...) # wrap the attention cell for decoding decoder_cell = GreedyDecoderCell(attn_cell) # call a special dynamic_decode primitive test_outputs, _ = dynamic_decode(decoder_cell, max_length_formula+1)Much better isn’t it? Now let’s see what
GreedyDecoderCellanddynamic_decodelook like.
Greedy Decoder Cell
We first wrap the attention cell in a GreedyDecoderCell that takes care of the greedy logic for us, without having to modify the AttentionCell
class DecoderOutput(collections.namedtuple("DecoderOutput", ("logits", "ids"))):
pass
class GreedyDecoderCell(object):
def step(self, time, state, embedding, finished):
# next step of attention cell
logits, new_state = self._attention_cell.step(embedding, state)
# get ids of words predicted and get embedding
new_ids = tf.cast(tf.argmax(logits, axis=-1), tf.int32)
new_embedding = tf.nn.embedding_lookup(self._embeddings, new_ids)
# create new state of decoder
new_output = DecoderOutput(logits, new_ids)
new_finished = tf.logical_or(finished, tf.equal(new_ids,
self._end_token))
return (new_output, new_state, new_embedding, new_finished)
Dynamic Decode primitive
We need to implement a function dynamic_decode that will recursively call the above step function. We do this with a tf.while_loop that stops when all the hypotheses reached <eos> or time is greater than the max number of iterations.
def dynamic_decode(decoder_cell, maximum_iterations):
# initialize variables (details on github)
def condition(time, unused_outputs_ta, unused_state, unused_inputs, finished):
return tf.logical_not(tf.reduce_all(finished))
def body(time, outputs_ta, state, inputs, finished):
new_output, new_state, new_inputs, new_finished = decoder_cell.step(
time, state, inputs, finished)
# store the outputs in TensorArrays (details on github)
new_finished = tf.logical_or(tf.greater_equal(time, maximum_iterations), new_finished)
return (time + 1, outputs_ta, new_state, new_inputs, new_finished)
with tf.variable_scope("rnn"):
res = tf.while_loop(
condition,
body,
loop_vars=[initial_time, initial_outputs_ta, initial_state, initial_inputs, initial_finished])
# return the final outputs (details on github)
Some details using
TensorArraysornest.map_structurehave been omitted for clarity but may be found on github
Notice that we place the
tf.while_loopinside a scope namedrnn. This is becausedynamic_rnndoes the same thing and thus the weights of our LSTM are defined in that scope.
Beam Search Decoder Cell
We can follow the same approach as in the greedy method and use
dynamic_decode
Let’s create a new wrapper for AttentionCell in the same way we did for GreedyDecoderCell. This time, the code is going to be more complicated and the following is just for intuition. Note that when selecting the top \(k\) hypotheses from the set of candidates, we must know which “beginning” they used (=parent hypothesis).
class BeamSearchDecoderCell(object):
# notice the same arguments as for GreedyDecoderCell
def step(self, time, state, embedding, finished):
# compute new logits
logits, new_cell_state = self._attention_cell.step(embedding, state.cell_state)
# compute log probs of the step (- log p(w) for all words w)
# shape = [batch_size, beam_size, vocab_size]
step_log_probs = tf.nn.log_softmax(new_logits)
# compute scores for the (beam_size * vocabulary_size) new hypotheses
log_probs = state.log_probs + step_log_probs
# get top k hypotheses
new_probs, indices = tf.nn.top_k(log_probs, self._beam_size)
# get ids of next token along with the parent hypothesis
new_ids = ...
new_parents = ...
# compute new embeddings, new_finished, new_cell state...
new_embedding = tf.nn.embedding_lookup(self._embeddings, new_ids)
Look at github for the details. The main idea is that we add a beam dimension to every tensor, but when feeding it into
AttentionCellwe merge the beam dimension with the batch dimension. There is also some trickery involved to compute the parents and the new ids using modulos.
Conclusion
I hope that you learned something with this post, either about the technique or Tensorflow. While the model achieves impressive performance (at least on short formulas with roughly 85% of the LaTeX being reconstructed), it still raises some questions that I list here:
How do we evaluate the performance of our model?. We can use standard metrics from Machine Translation like BLEU to evaluate how good the decoded LaTeX is compared to the reference. We can also choose to compile the predicted LaTeX sequence to get the image of the formula, and then compare this image to the orignal. As a formula is a sequence, computing the pixel-wise distance wouldn’t really make sense. A good idea is proposed by Harvard’s paper. First, slice the image vertically. Then, compare the edit distance between these slices…
How to fix exposure bias? While beam search generally achieves better results, it is not perfect and still suffers from exposure bias. During training, the model is never exposed to its errors! It also suffers from Loss-Evaluation Mismatch. The model is optimized w.r.t. token-level cross entropy, while we are interested about the reconstruction of the whole sentence…
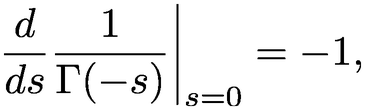 |
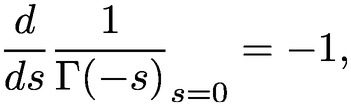 |